

PhD Thesis Project: Interaction of Loudspeaker and Microphone Arrays for Teleconferencing Applications

|
A Project by ...Markus Noisternig, noisternig [at] iem.at
SupervisorsProf. Dr. Mag. Robert Höldrich, hoeldrich [at] iem.at Institute of Electronic Music and Acoustics (IEM) Gernot Kubin, gernot.kubin [at] tugraz.at Signal Processing and Speech Communication Laboratory (SPSC Lab) Dr. Martin Opitz AKG Acoustics, Vienna
Contact detailsInstitute of Electronic Music and Acoustics (IEM) Inffeldgasse 10/3, 8010 Graz, Austria email :: noisternig [at] iem.at phone :: +43.316.389.3681 mobile:: +43.664.5301110 |

Abstract
Hands-free speech communication is a challenging task in real-world environments, e.g. robust desktop conferencing or in car communication. The highly time-variant nature and characteristics of disturbing environmental noise, room reverberation and the acoustic coupling between loudspeakers and microphones result in substantial speech signal distortion.
Project outline:
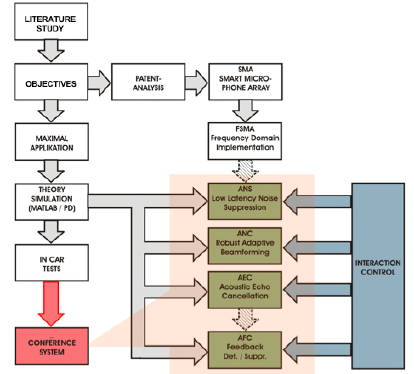
[Click for larger view]
![[Click for larger view]](overview_lg.png){kind=link}
One of the most important problems in acoustic MIMO signal processing is to extract a desired speech signal and reduce the effects of unwanted noise and acoustic echoes. Speech enhancement can be performed using spectral subtraction or temporal filtering such as single-channel Wiener filtering or multi-microphone methods using a variety of different array techniques. Acoustic feedback is handled by conventional echo cancellation techniques but also taking the interaction with the adaptive beamforming algorithms into account (e.g. joint optimization). Room reverberation, degrading the robustness of the speech communication front-end, is most effectively addressed by using array techniques, especially by improvements on the Generalized Sidelobe Canceler's adaptation mode control.
To reduce the vocal effort during conversations in noisy environments, the enhanced near-end speech signal is fed back to the local talker's position with minimum delay. This approach requires lowest-latency speech enhancement algorithms. To address the problem of howling and ringing different sub-band approaches using adaptive notch filters are used.
In conclusion, this project effectively combines spatial and temporal processing to address the above mentioned problems very efficiently.
Structure:
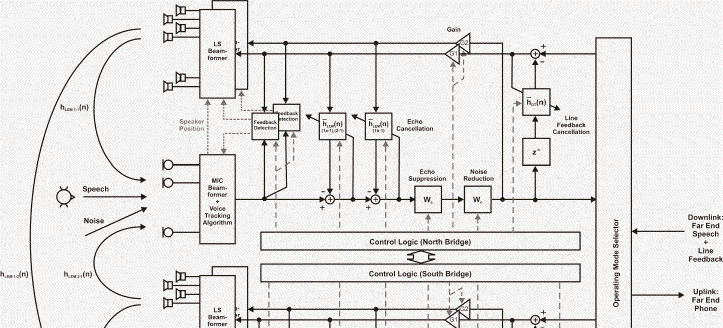
[Click for larger view]
![[Click for larger view]](max_appl_large.png){kind=link}
We propose ...
A Robust Adaptive Beamforming front-end for full-duplex speech communication in teleconferencing and automotive applications, based on Constrained Minimum Variance Beamforming in form of a Generalized Sidelobe Canceler (GSC). To provide stability and robustness in reverberant environments we improved the Adaptation Mode Controller, that enables the Blocking Matrix (BM) and the Multiple Input Canceler (MC) to adapt alternately, depending on target signal occurrence. Our approach is highly transparent for speech onsets (transients).
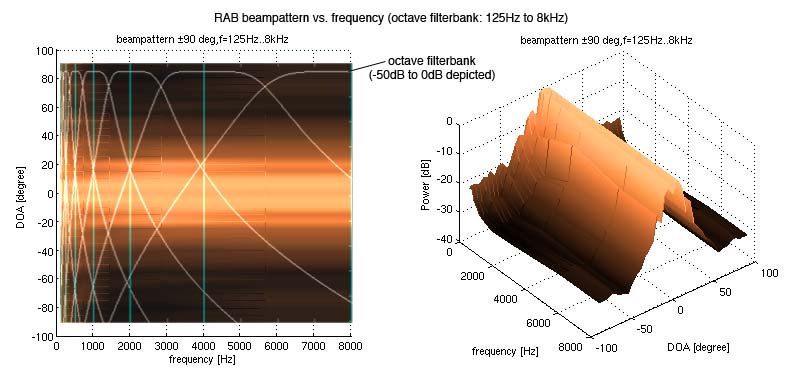
Figure: Measured performance of the Robust Adaptive Beamformer (RAB). Variance of octave-band filtered output signal vs frequency and direction of arrival.
Further speech enhancement is obtained by post-processing the array output by sub-band low-latency single-channel noise suppression filters in an auditory domain. Using Ephraim and Malah's Spectral Subtraction Rule (EMSR-DDA) we propose low-latency level detection in each subband, auditory masking, computationally efficient amplitude estimation very similar to Wolfe and Godsill's approach, plus a modified Decision Directed Approach (DDA).
Acoustic Echo Cancelers eliminate echos and allow full-duplex communication. This device is composed of (1) an adaptive filter to estimate the acoustic echo path, (2) a double-talk detector to avoid divergence of the adaptive filter, and (3) non-linear processing to further attenuate the residual echo. We propose a Proportionate Block Frequency Domain Normalized Least Mean Square Algorithm (PBFD-NLMS) with Insertion of Probe Signal and Pseudo Optimal Step Size Control. Further, the AEC plus MC algorithms are joint optimized.
To avoid howling and ringing Feedback Detection algorithms plus post-filters are implemented. We introduce algorithms capable to track and suppress ringing efficiently.
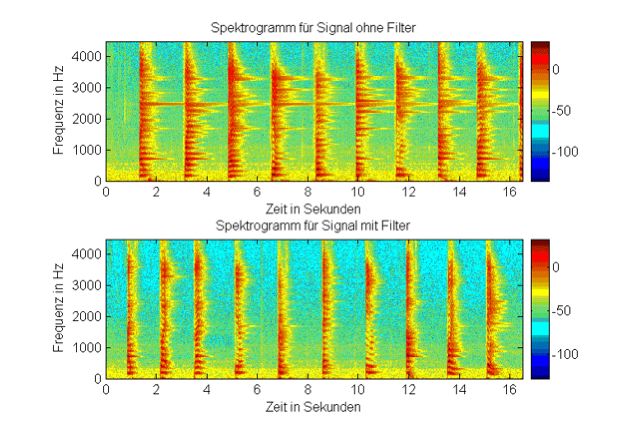
Figure: Spectrogram of speech signal without / with Anti-Ringing Filter
Audio Examples:
Audio Examples in .mp3-format ...
- Speech signal disturbed by ringing, without Anti-Ringing Filter
- Speech signal disturbed by ringing, with Anti-Ringing Filter
Credits
Special acknowledgement is given to my former undergraduate students Franz Zotter and Lutz Pape for their assistance throughout this project.